
What is HPCINFRA
At HPC Infra, we are revolutionizing the chip development ecosystem by providing a cloud-agnostic, scalable infrastructure stack that integrates seamlessly with your existing tools and workflows. Whether you’re running on-prem, cloud, or hybrid environments, we ensure flexibility, lower costs, and faster time-to-market
What the Platform Does
The Platform distributes high-performance workloads across multiple machines and make them run faster.
Building a SLURM Cluster on AWS: A Journey from Manual Setup to Automated Deployment
So we recently embarked on a journey to create a SLURM cluster on AWS, evolving it from a basic manual setup to a fully automated, library-driven solution. Here’s my story of how we transformed a basic cluster into a production-ready system.
Quick Tech Overview:
- SLURM: An open-source job scheduler for Linux that manages and schedules computing tasks across multiple machines.
- AWS (Amazon Web Services): A cloud platform providing on-demand computing resources and services.
- Terraform: Infrastructure-as-Code tool to create and manage cloud resources through code.
- Ansible: Automation tool for configuring servers and deploying applications.
Initial Manual Setup
Having worked with AWS before, we started with the basics: manually creating EC2 instances. After diving into the SLURM documentation, we learned that we needed at least two machines: one to serve as the controller (slurmctld) and another as the compute node (slurmd).
We launched two Ubuntu 22.04 LTS instances and began the setup process. The head node got slurmctld, while the compute node received slurmd. The real challenge came in establishing communication between these nodes. To facilitate this and ensure proper job handling, we implemented shared storage mounted across all nodes to store job results.
First Success and Moving Towards Automation
After getting the basic configuration right, we ran a sample job — and it worked! This success was exciting, but we knew manual setup wouldn’t scale. That’s when we turned to infrastructure as code, using Terraform for provisioning and Ansible for configuration management.
Creating a Reusable Solution
The next evolution was developing a Python library that abstracted away all the complexity. The library allowed users to create SLURM clusters by simply specifying three parameters:
- Machine size
- Number of nodes
- Shared storage size
To optimize deployment speed, we created custom AMIs for both compute and head nodes. This dramatically reduced cluster startup time to just minutes, making it practical for on-demand use.
Enhanced Features and Monitoring
We wanted to track cluster usage, so we implemented job logging to an RDS instance. Instead of setting up the more complex slurmdbd and SLURM REST API, we opted for a simpler solution: a Python script that captures and stores job-related environment variables. This gave us the monitoring we needed without the overhead of maintaining additional SLURM components.
AI-Powered Cluster Interface
To make the cluster even more user-friendly, we integrated an AI chatbot using OpenAI’s function calling capabilities. This addition transformed how users interact with the cluster:
User: “Show me the status of my recent jobs”
Bot: *Here are the statuses of your recent jobs:
1. Job ID 26 — Name: testjob1 — Status: COMPLETED
2. Job ID 25 — Name: testjob2— Status: COMPLETED
If you need more details about any specific job, feel free to ask!*User: “Which projects are currently active?”
Bot: *Your currently active project is:
1. Example Project — This is an Example Project. — ACTIVE
If you need more details about this project, feel free to ask!*
The chatbot handles common queries through predefined function calls, making cluster management more intuitive. Instead of remembering specific commands or navigating through interfaces, users can simply ask questions in natural language. The system is designed to be extensible — as we add more functionality to the cluster, we can easily expand the chatbot’s capabilities by adding new function definitions.
User Management and Final Form
The last piece of the puzzle was adding multi-user support. We extended our library to include functions for adding new users’ public keys to the cluster, making it truly multi-tenant capable.
The End Result
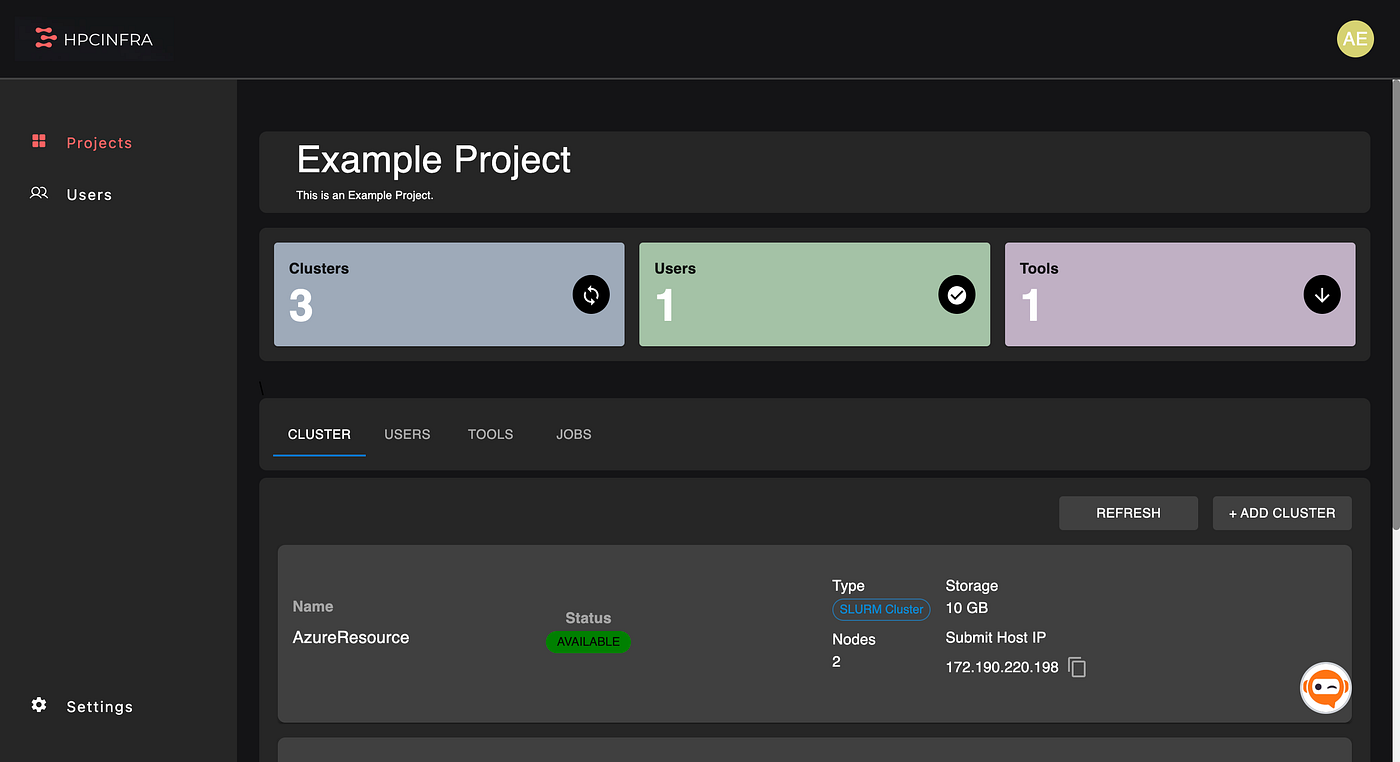
What started as a manual two-node setup evolved into a solution with:
- Single-function cluster provisioning
- Automated configuration management
- Quick startup using custom AMIs
- Job logging and monitoring
- Multi-user support
- Flexible node scaling
The entire system can now be deployed with minimal input, making SLURM cluster creation accessible to teams without deep AWS or SLURM expertise. What’s particularly satisfying is how we maintained simplicity while building a production-grade system — everything from cluster creation to user management can be handled through simple library calls.
This journey taught me that while building a basic SLURM cluster is straightforward, creating a production-ready system requires careful consideration of automation, monitoring, and user management. By focusing on simplicity and user experience, we created a solution that makes high-performance computing more accessible to our entire organization.
 2026 Hamon Technologies Inc
2026 Hamon Technologies Inc